


Deploy! Intelligence too cheap to meter @ $0.0001 per million tokens.
Part II: AI 2030: Scale, Deploy and Secure. aka how I learned to stop worrying and carry on writing theses
You came for the Micheal Jackson linkedin post, and stayed for the jokes. That’s good, come in the water’s warm. Some people call me the Matt Levine of Deep Tech. Others call me a fraud. Those would be unkind people. Crypto man, those kids can be cruel.
Before you crack on, there are actual people who really know their semi onions, I can’t recommend
and enough, if you really want to know your CoWoS-L from your EMIB. Your HBM from your MBH. But, also stick around. I like to think the meso-level is the real action. That’s the trick isn’t it. Just speak faster and people think you know what you’re talking about. Speak at some level of detail about lots of subjects. The Gell-Mann Amnesia effect. That’s my career.Anyway, the rest of this is definitely accurate. Last week, I told you about the 100GW AI Factories we were all gonna build because we gotta build them before the CCP remember? Suggest if you haven’t to read it first. I’ll wait.

Welcome Back as Mase once said. Today, the story continues. Let's assume we’ve built these AI factories and are feeding 10-100 GW to our new God in the Sky. It will all be for nought if it costs a fortune to use it.
The labs have done remarkably well on the cost front already, with the cost for 2 million tokens (input+output) decreasing from $180 to $0.75 in 2 years. 240x cheaper is some serious numbers.
But it’s not enough, just like we will need unprecedented power generation, distribution and delivery, we are going to need to throw everything at reducing costs.
I’m out here at $0.0001 per million tokens. It’s not a useful number. It’s just a low number. Throw another zero if you fancy. But basically we are talking “too cheap to meter”. Only when it’s this cheap can it be integrated into all the internet of all the things. Like the IoT always prophesied.
Gods don’t have usage caps.
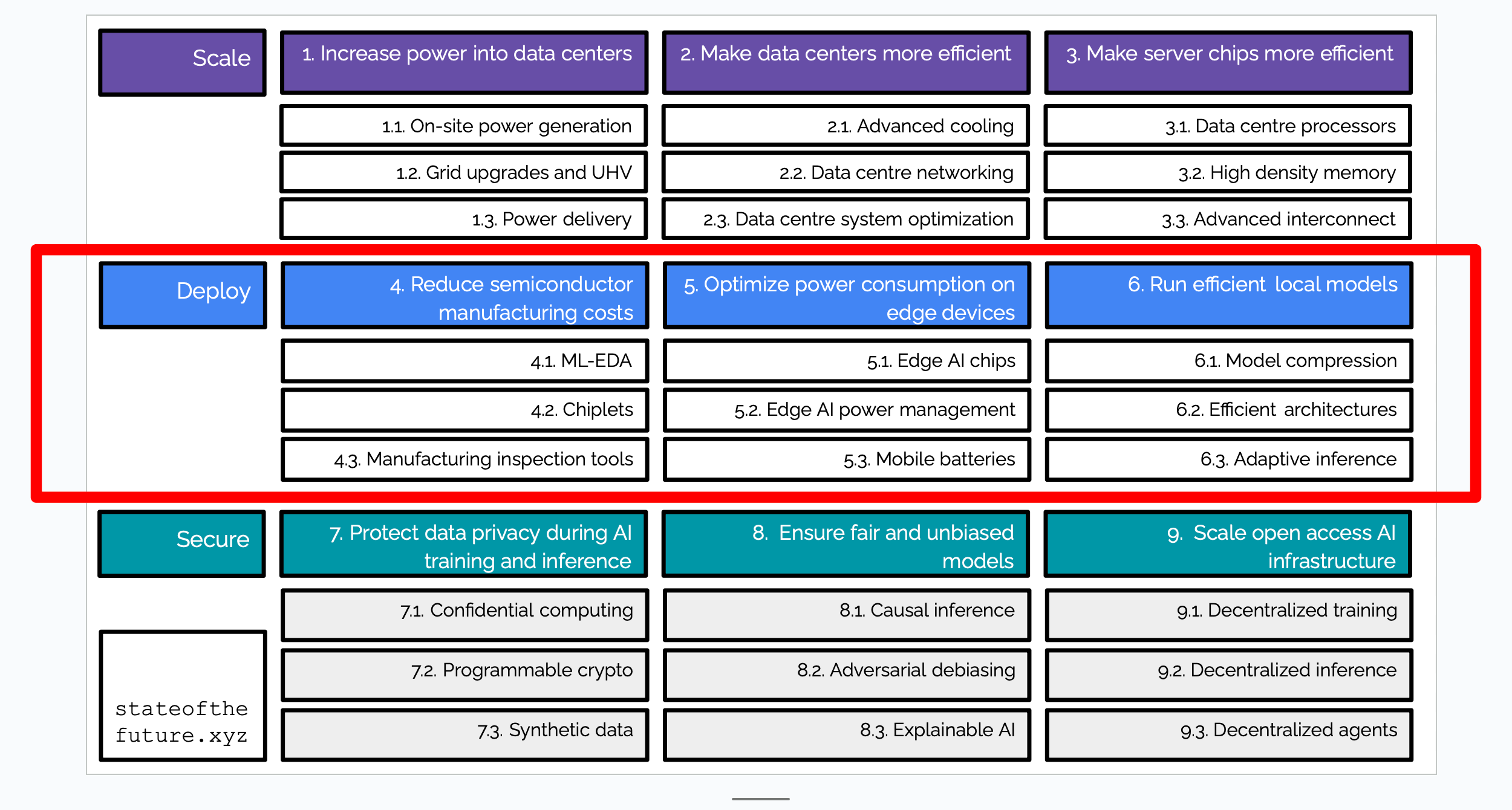
So I asked around and figure we have to solve three big things if we want always-on, pervasive AI everywhere. Seer the red box in the graphic above.
How do we reduce the costs of making semiconductors?
How do we optimize power consumption of edge devices?
How do we build smaller, more effecient models to run locally on edge devices?
In future editions, imma go into more depth into each solution area. So don’t DM me and go: “lawrence, why don’t you go into more depth on Multi-beam electron microscopy.” Answer: pay me if you want early access. Otherwise you will like everyone else. And I’m expensive.
4. Reduce semiconductor manufacturing costs

It’s not really remarked upon, but like, it’s super expensive to make cutting-edge chips. Should it be? Why should it be getting more expensive? Making small things is harder and more expensive than making big things. Nice one yea. They always say “ask stupid questions, think like a beginner”. So, here I am, asking: can we make chips for cheap?
The cost of semiconductor manufacturing has escalated dramatically over the past few decades, driven by the increasing complexity of chip designs and the need for more advanced fabrication processes. As transistor sizes shrink to atomic scales, the equipment and facilities required to produce has become more expensive. A single new NA-EUV lithography machine costs over $150 million. Building a state-of-the-art semiconductor fab costs over $20 billion. The average cost per wafer at 5nm costs is around $16k, 60% jump from 10k at 7nm. Lots of numbers, sure. But the point is, making chips has got more expensive and is the limiting factor to experimentation creating a high barrier to entry and increasing the risk of experimentation with novel designs or materials. To be honest, this is a super tricky one. It’s not obvious how to dramatically decrease the costs of semiconductor manufacturing. I’ve heard about moving away from photolithography to fancy things like direct-write electron beam lithography (EBL) and Advanced Nanoimprint Lithography (NIL) to enable economical low-volume production, but these technologies are still very immature. (Unless some fabs have advanced prototypes, if so DMs open pls)
4.1. ML-EDA
So let’s start with electronic design automation (EDA). Well the first problem you have is a oligopoly with Synopsys, Cadence, and Siemens at 70% market share but even more for the most sophisticated chips at advanced nodes. One doesn’t simply design a chip unless it works with the Big3. And even if you create a new widget, they will buy you. And even if you create an even better widget, a multi-physics simulation tool with the potential to disrupt chip design through simulation, they will buy you. $35 billion for Ansys. It’s a graveyard of well intentioned startups that asked: surely, shipping hardware should be as easy as shipping software? But is this time different, does AI or as they call it in EDA, ML-EDA, present a disruptive force? Maybe. Designing chips isn’t get easier. The chips are getting smaller, they are being connected up in weird ways with chiplets, and then connected up over scale out fabric. EDA optimization is a multi-dimensional challenge. As fabrication techniques get more complex at advanced nodes and components get increasingly vertically stacked and connected up in all sorts of ways, designers are thinking in terms of systems and systems of chips, rather than at just the circuit and logic level. It’s not AI per se that is disruptive, but the shift to systems-not-chip is disruptive. The entry point for thinking about performance and cost for AI systems moves from the chip itself to the enture device and how the device interacts with another devices. This shift potentially opens up room for new EDA entrants to bring down design costs. through advanced design for manufacturability (DFM) techniques, automated design space exploration, and unified multi-physics simulation.
Buy: Design for Manufacturability (DFM) Optimization; Automated design space exploration; Unified multi-physics simulation
Track: AI-Driven IP Reuse and Integration; Automated Analog and Mixed-Signal Design
4.2. Chiplets
Chiplets represent a “paradigm shift” in semiconductor design and manufacturing, moving away from monolithic system-on-chip (SoC) designs towards modular, multi-die architectures. I know I know, but this one actually is a paradigm shift. “Paradigm shifts arise when the dominant paradigm under which normal science operates is rendered incompatible with new phenomena, facilitating the adoption of a new theory or paradigm.” so says my old friend Thomas Kuhn. Old = SoC. New = chiplets.
"Started for Ten: Is AI a paradigm shift? If so from what to what?* (Answer will probably determine your 2x funds from your 10x’s.). I HOPE if you are investor you have a good answers, otherwise what are you doing out there!"*
In this approach, complex chip designs are disaggregated into smaller, specialized dies (chiplets) that are integrated within a single package using advanced packaging technologies. This strategy allows for the optimization of each chiplet for its specific function and fabrication process potentially reducing overall costs and improving yield. Chiplets enable the mixing of process nodes, IP blocks, and technologies from multiple vendors within a single package, offering flexibility in chip design and potentially reducing time-to-market for new products.
Buy: Heterogeneous integration of different process nodes; Standardized chiplet interfaces; Advanced packaging technologies
Track: "Known Good Die" (KGD) testing methodologies like wafer-level testing and built-in self-test (BIST) circuits; Graphene-based interconnects, Direct-write electron beam lithography (EBL), Advanced Nanoimprint Lithography (NIL)
4.3. Manufacturing Inspection Tools
ML-EDA and chiplets should get us to tape-out quickly and cheaply. But many exciting logic or memory designs died because scale. By didn't scale, I mean it was too difficult to manufacture at high volumes, We can expect EDA and multi-physics simulation tools to catch issues before getting to the fab. But the single biggest issue for fabs is yield management because it directly impacts the economic viability of production. Yield, the percentage of functional chips produced on a wafer, is crucial for profitability in an industry with outrageously high fixed costs $10k at 7nm, $16k at 5nm, and estimates of $20k for 3nm. A typical 300mm wafer might contain thousands of dies, depending on their size. If yield drops from 90% to 70%, the cost per good die can increase by 30% or more, potentially turning a profitable product into a loss-maker. Even a 1% improvement in yield can translate to millions of dollars in savings for high-volume production. At 5nm and below, features are so small that atomic-level defects can cause chip failures. As chip designs become more complex, with billions of transistors and multiple layers, the probability of defects increases, making yield management even more critical. Among the potential solutions are AI-powered defect classification systems, multi-beam electron microscopy, and photoluminescence imaging.
Buy: AI-powered defect classification systems, Multi-beam electron microscopy, Photoluminescence imaging (this is actually super interesting)
Track: Acoustic microscopy; X-ray computed tomography (CT)
5. Optimize power consumption on edge devices

Right, honestly this is where the startup and VC ecosystem has been focusing. Semi manufacturing is left to TSMC. I present to you a more exciting opportunity. New chips to eat into that lucrative edge chip market. As you will all be aware, edge devices can’t run high performance models because they use too much power, compute and memory. For smartphones it’s a problem. But for watches, headphones, and glasses it’s a dealbreaker.
In smartwatches, the total SoC area is typically limited to 50-70 mm², with AI accelerators needing to fit within 2-3 mm². Power budgets for AI tasks are often constrained to 50-100 mW, necessitating performance in the range of 1-2 TOPS/W. The constraints become even more severe for devices like earbuds or glasses. In these form factors, the entire SoC, including the AI accelerator, might need to fit within 10-20 mm². Power consumption for AI tasks must be limited to 10-20 mW to maintain acceptable battery life, pushing the efficiency requirements to 5-10 TOPS/W or higher. Now, the good news is Nvidia doesn’t own the edge chip market. But the bad news it’s super fragmented across a ton of small and disparate application areas. But, I’m thinking maybe now is the time. What if. And this is the 1st slide on the pitch deck deck btw: “Nvidia. But for the Edge” You’re welcome again.
5.1. Edge AI Chips
So we need new chips to meet the latency and power requirements for always-on, always-watching, always-listening AI on our devices. Each device will need a dedicated chip, Apple is likely the model for the industry with A range for the iPhone, H range for airpods, M for laptops, R for mixed reality headsets, S range for watches. We can expect further specialization over the next few years. These SoCs combine CPU, GPUs, wireless comms, memory, and a so-called neural engine, which I think we are all now calling a neural processing unit (NPU) for the GPU to offload some AI tasks. As with data center AI designs, there is plenty of room for optimization. We will almost certainly see edge AI accelerators in the market optimized for a broad range of AI offloading tasks. The challenge is deciding how specific the design needs to be to meet performance, latency and power requirements whilst maintaining some level of programmability to run a variety of algorithms. So we may see the NPU become dominant as a “general-purpose” AI accelerator, or a variety of “application-specific accelerators” for voice conversations or for image recognition or for biosignal tracking. The most interesting areas are in-memory computing (IMC), neuromorphic accelerators such as event-based cameras, and analog accelerators.
Buy: In-memory computing (IMC); Neuromorphic chips and event-based cameras; Analog AI accelerators (I’ll go into each of these over the next few weeks)
Track: Compute-in-sensor AI; Ultra-low power microcontrollers with AI acceleration
5.2. Edge AI Power Management
While eveyone is focused on cool new chips. What about plain old, dynamic power management. It’s a massively underexplored area to improve the power consumption of edge devices. We can offload algorithms to accelerators and use novel designs and even waves instead of electrons to process information. Or we can do power management better. Well it’s not either or really, it’s both. But still it’s a low-hanging way to squeeze much more from our batteries. For context, a typical smartphone battery capacity ranges from 3000 to 5000 mAh, while AI tasks like real-time image recognition or natural language processing can consume up to 2-3 watts during peak operation. This power draw can reduce battery life from days to mere hours if not managed efficiently. To grossly simplify (you might notice that’s a pattern here) the thermal design power (TDP) of most mobile SoCs is limited to 2-5 watts, necessitating sophisticated power management to prevent thermal throttling and maintain consistent performance. These constraints have spurred the development of advanced power management solutions that aim to maximize energy efficiency without compromising the user experience.
Buy: Predictive power management systems; Transistor-level fine-grained power gating; Adaptive body biasing
Track: Context-aware power policies, Energy-aware task scheduling and load balancing, Near-threshold computing
5.3. Mobile Batteries
Instead of new chips or better power management, what about we try again with chemistry. Hello emerging batteries my dear friend. We’ve been expecting you. Nuclear batteries! Coming out of China. We were promised flying cars, etc. Maybe now with the low-carbon transition and all the money being poured into EVs, it is the time. Maybe the market is large enough and growing fast enough that we can finally scale up one of these novel battery chemistries. However, the dominance of lithium-ion technology in the current ecosystem of consumer electronics and EVs presents a significant barrier to new battery technologies. Economies of scale have driven lithium-ion battery prices down to unprecedented levels, with costs falling below $100 per kWh for electric vehicle batteries in 2020. This price point was previously considered unattainable. Consequently, emerging battery technologies face not only the challenge of achieving manufacturing scale but also at a super low price point. And the robust supply chain, manufacturing infrastructure, and continuous improvements in lithium-ion technology further compound this challenge for new entrants in the battery space. That said, the size, performance, and power requirements differ so widely between devices that I can’t imagine a world in which lithium-ion is the only battery technology. Heterogeneity is the watchword. Eventually, a world in which big devices use solid-state batteries, medium sized ones use silicon anode batteries, tiny wearables use lithium-sulfur batteries each optimizing for density, weight, safety and cost. Now, when will we see this world? Well, that’s the job. That’s the job.
Buy: Solid-state batteries; Silicon anode batteries; Lithium-sulfur batteries
Track: Quantum dot photovoltaics; Thermoelectric fabrics; Wireless power transfer technologies; Nuclear batteries (Yes for reals “Chinese startup Betavolt recently announced it developed a nuclear battery with a 50-year lifespan.”Chinese startup Betavolt recently announced it developed a nuclear battery with a 50-year lifespan.”
6. Run efficient local models

Last one for you edification. Compression basically. If we run 4 and 5, more, cheaper chips, and batteries that run for longer, we are moving alot of atoms around. That’s expensive. Or we could just like, make the models smaller no? Seems like the easiest option imo. GPT-4 has over 1 trillion parameters, requiring hundreds of gigabytes of memory for storage and potentially consuming up to 2,000 watts during inference. For context, the iPhone 15 Pro has 8GB of RAM and a total power consumption under 5 watts, while even the most advanced smartwatches have less than 2GB of RAM and operate on milliwatts of power. So yeah this is a trend already. We’ve seen Gemini Nano, GPT-4 mini, Claude Haiku, and TinyLlama. These models can be 10-100x smaller than their larger siblings offering good enough performance. But the larger models are still much much better. While hardware engineers work on optimized chips and better batteries, there's substantial work to be done on the algorithmic front. The algorithmic overhang as it’s known.
6.1. Model Compression
Model compression is a crucial technique for deploying large AI models on resource-constrained devices. As language models grow exponentially in size, it’s not obvious that generation5 model parameters will be orders of magnitude larger than gen4, but I doubt they will get smaller. So maybe a trillion parameters is the baseline and we go up from there more slowly. Gen5 and 6 models will start to become so-called compound systems combining chain-of-thought, reinforcement learning, and thus we shouldn’t expect exponential scaling. But still, let’s compress them no? If we can, sure why not? Trade off some small performance gains that will become increasingly marginal for most use cases and users for 2-3-10x decrease in power consumption. Recent breakthroughs include Google's UL2R, which compresses the 540-billion parameter PaLM model to just 8 billion parameters while retaining 90% of its capabilities. Also see Microsoft’s BitNet the 1-bit LLMs. . These advancements are enabling the deployment of powerful AI capabilities on smartphones and soon to be glasses, earpods and watches. Let’s take a closer look at quantization, pruning and knowledge distillation in particular.
Buy: Quantization; Pruning; Knowledge distillation
Track: Low-rank factorization ; Hashing-based compression; Neural architecture search (NAS)
6.2. Efficient Architectures
Efficient architectures cover the broad research area of creating neural network structures that inherently require less computation and memory. As we know, and Nvidia's stock price can testify, traditional transformer models, while highly effective, suffer from quadratic complexity in self-attention mechanisms, making them impractical for long sequences or resource-constrained environments. Recent innovations in this space demonstrate how architectural changes can lead to models that are not only more efficient but also more aligned with deployment on resource-constrained hardware. Notable examples include MatMul-free language models, which replace matrix multiplication operations with more efficient alternatives, significantly reducing computational requirements while maintaining model quality. Parameter-Efficient Fine-Tuning (PEFT) techniques, such as LoRA (Low-Rank Adaptation) and prefix tuning, allow for adaptation of large pre-trained models to specific tasks with minimal additional parameters, greatly reducing memory footprint and training time. Sparse Mixture of Experts (MoE) models, like GShard and Switch Transformers, employ a divide-and-conquer approach by routing input to specialized sub-networks, enabling the scaling of model capacity without a proportional increase in computation.
Buy: MatMul-free language models; Parameter-efficient fine-tuning (PEFT); Sparse mixture of experts (MoE) models
Track: Linear Transformers; Continuous token mixing models; Quantum-inspired tensor network
6.3. Adaptive Inference
Also while we are on the subject. Why use fixed computational paths when the workload compute requirements vary wildly? Good question. Adaptive inference dynamically adjusts computational resources based on input complexity or task requirements, crucial for deploying models on resource-constrained devices. Unlike static models that use fixed computational paths, adaptive inference systems modulate their operations in real-time, effectively "thinking" as hard as necessary for each specific input. Key techniques in this field include early exit mechanisms, which allow models to terminate processing once a confident prediction is made; conditional computation, which selectively activates relevant parts of the network; and dynamic neural network compilation, which optimizes network structure on-the-fly. Recent implementations like Google's CALM, Microsoft's DynaBERT, and Nvidia's BART showcase how these approaches can maintain high accuracy while significantly reducing inference time and energy consumption, paving the way for more efficient and ubiquitous AI applications.
Buy: Early exit mechanisms; Conditional computation; Dynamic neural network compilation
Track: Neuromorphic adaptive computing; Quantum-inspired adaptive algorithms; Adaptive precision techniques
Thanks everyone for your continued support. And those of you that don’t support me remember “You are an aperture through which the universe is looking at and exploring itself.”
Next week:
How do we protect data privacy during training and inference?
How do we ensure fair and unbiased models?
How do we scale open access AI infrastructure? (Hint: crypto. It’s back)
And with that.
