
The Compute Gradient
What if it's not all about building bigger and bigger datacentres? What if you can win in AI without competing on 10bn+ capex projects?


hi all, i’m making the world better for my kids by investing in what other investors also want to invest in so I can get mark-ups. lol. saying the quiet part out loud since 2025. get in touch.
This is a joint post with Jonno Evans over at techpolitik. I dunno what Jonno is doing over there, maybe he’s doing something different. ask him.
I. Rethinking AI’s Energy Problem
In July, Jonno wrote in The Energy Theory of Everything that:
“Intelligence is a function of electricity. AI turns energy into intelligence. 0.3 Wh is the electricity cost of a single GPT-4o query. Now imagine an AI agent that fires 100 calls per task, with a power user running 1 00 tasks daily. That is 3 kWh per user per day. Scale to one million users and the total hits 1.1 TWh a year – Oxfordshire’s household demand – before you even count model-training. The IEA expects global data-centre demand to double to 945 TWh by 2030 even taking into account potential hardware efficiency gains.”
Lawrence (hi ma!) called bullshit. In the debate that followed (raged), we agreed that Lawrence was completely partially right - it is a bit more nuanced.
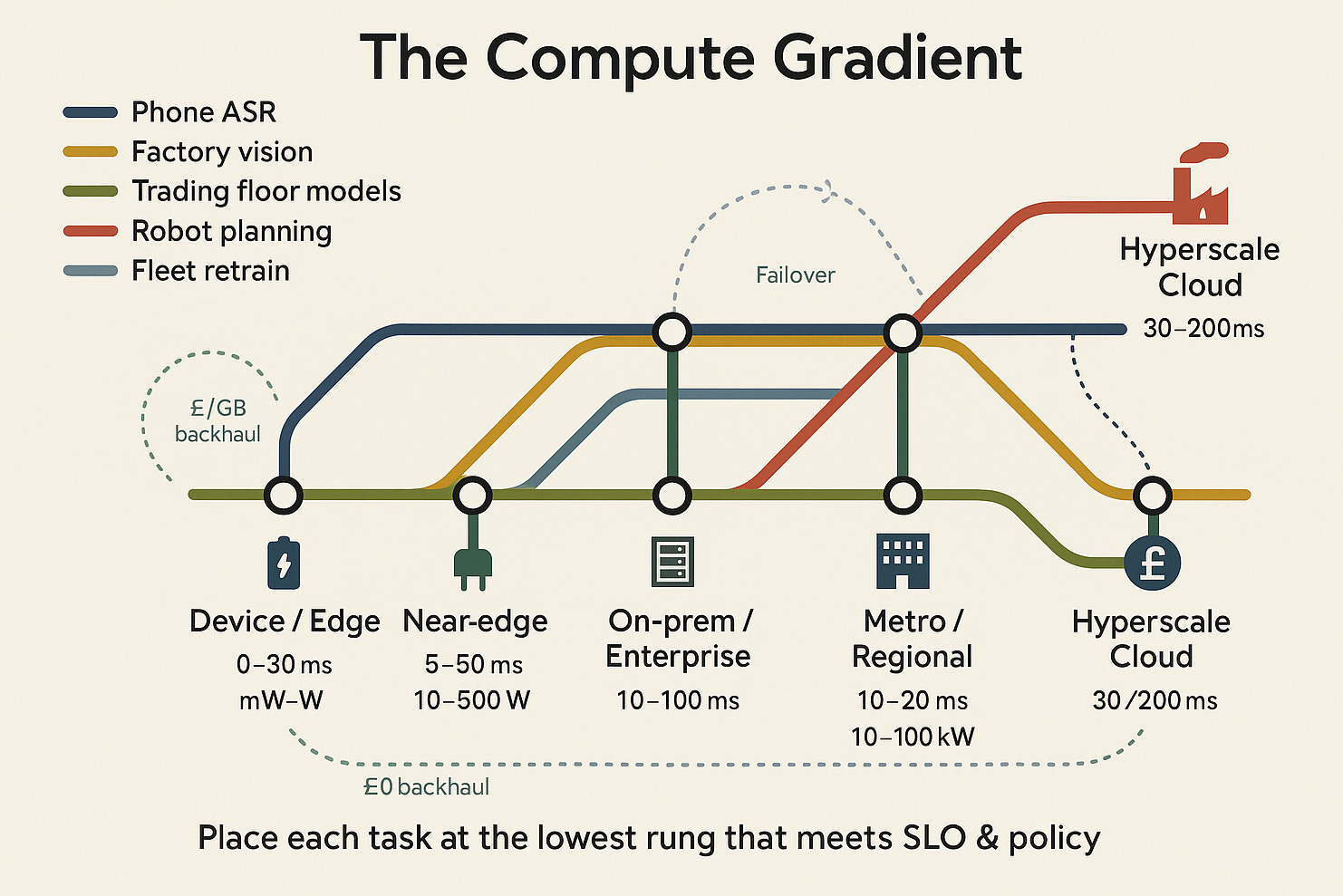
One way to rethink the problem is through what might be called ‘The Compute Gradient’.
Our claim: inference shouldn’t be assumed “in the cloud” or even “mostly in the cloud.” It should be placed along a gradient - dynamically - based on policy and physics: latency budgets, privacy/regulatory constraints, data gravity, link quality/cost, power, and failure tolerance.
“Programmable” means you can move workloads, split them, or fail them over, at build-time and at run-time.
Edge: Your phone, headset, or car runs models locally, instant response, private, but power-limited.
Near edge: A cell tower or factory gateway processes streams nearby, low delay, modest compute.
Access: Think enterprise edge & co-lo: A server rack in a hospital or trading floor, keeps data on-site, but costly to run.
Regional hubs: A city-level data centre, good balance of compliance and speed, medium capacity.
Hyperscale: The vast cloud mega-centre, huge power and latest chips, but farther away and pricier to move data.
Distributed and federated approaches will cut across the gradient. Instead of pulling all data into the cloud, models train or infer locally and only share updates. Google’s Gboard keyboard as we all know and love, or Apple’s Private Cloud Compute blends on-device and secure server inference. These patterns let intelligence improve collectively without centralising raw data, pushing compute closer to where information originates.
II. The Compute Gradient
The energy-intelligence equation driving current AI infrastructure panic contains a critical assumption: that inference happens "in the cloud" or "mostly in the cloud." This assumption needs challenging. So here we are.
The right place to run inference depends on latency, performance, security, power and cost, creating what we might call The Compute Gradient. Edge devices provide instant response and privacy but limited power. Near-edge processing at cell towers or factory gateways offers low delay with modest compute. Access points like enterprise servers keep data on-site but cost more to run. Regional hubs balance compliance and speed with medium capacity. Hyperscale datacenters deliver vast power and highest performance chips but sit farther away with higher data movement costs.
The question isn't whether we can break the link between energy and intelligence, but whether The Compute Gradient changes the economics fundamentally. If inference can be distributed intelligently across these five points, the problem stops being binary.
This isn't a revolutionary insight. Millions of engineers already understand that running algorithms on-device improves latency. But in the current frenzy of infrastructure buildout, it's time to remind people where this is going. The trajectory towards Stargate-class datacenters with 72-144 GPUs per rack, burning through megawatts per pod, may prove a miscalculation. Then again, Jevons Paradox suggests that as inference gets cheaper, we'll simply use more of it, meaning we can't possibly overinvest yet. The latter seems more likely at this point.
But three trends are pushing the industry towards the edge. First, computation placement cuts energy waste by moving algorithms to data rather than data to algorithms. Phones now handle speech recognition locally. Tesla processes video onboard rather than streaming footage to remote servers. Cloudflare pushes inference into city-level nodes. Each case demonstrates the same principle: placing compute closer to data reduces latency, cost, and power consumption.
Second, chip efficiency improvements multiply these gains through better hardware architectures. Companies can use photons instead of electrons for computation, though this remains technically challenging. Others like Lightmatter and Celestial convert electrons to photons for data movement, essentially fiber optics between servers and chips. Some approaches like those from Fractile, Semron, and D-Matrix eliminate alot of data movement by integrating memory directly into processing units. Neuromorphic computing often uses similar in-memory primitives. Additional approaches include stacking memory vertically through high-bandwidth memory (HBM), processing data at sensors, or using analog rather than digital computation. There are a ton of options for reducing the energy cost per operation.
Third, model compression techniques push more capability toward power-constrained environments. Smaller architectures, pruning, sparsity, and quantization enable more edge deployment while reserving datacenters for workloads requiring true scale. Two-bit and four-bit inference are moving into production. Compilers like TVM, MLIR, and Modular optimize kernels for each point on the gradient. Distillation maintains accuracy while shrinking model size. Mixture-of-Experts and early-exit architectures activate only necessary parameters per request. Retrieval-augmented generation stores knowledge in external corpora rather than model weights. Lightweight adapters and LoRA enable task switching without full model retraining, ideal for edge deployments under tight power and bandwidth constraints.
Hundreds of billions in R&D investment are targeting exactly these inference economics improvements. Taken together, these advances make it increasingly plausible that more compute migrates toward the edge, with hyperscale datacenters reserved for the highest performance workloads.
Pushing inference to the edge doesn't eliminate electricity consumption. The cost of a FLOP remains the cost of a FLOP. What changes is where and how that power gets consumed, and crucially, who pays for the infrastructure. The overall system can become more energy efficient, but the power draw burden shifts from hyperscale operators to distributed devices, gateways and regional servers. Less concentration of megawatts in few datacenters, more spread of milliwatts and kilowatts across billions of devices.
In other words, less concentration of megawatts in a few datacentres, more spread of milliwatts and kilowatts across billions of devices.
Whether this reduces total energy consumption depends on more than workload mix and model size. Energy sourcing matters significantly. Hyperscale datacenters can access dedicated gas, nuclear, hydro or geothermal power sources. Edge devices typically charge through lossy converters connected to standard grids. Centralisation can therefore unlock power-sourcing efficiencies that distributed devices cannot achieve. (See, Lawrence wasn’t totally right). But the economic distribution definitely changes, with hyperscalers bearing vast energy contracts versus enterprises, factories and households sharing costs at the edge.
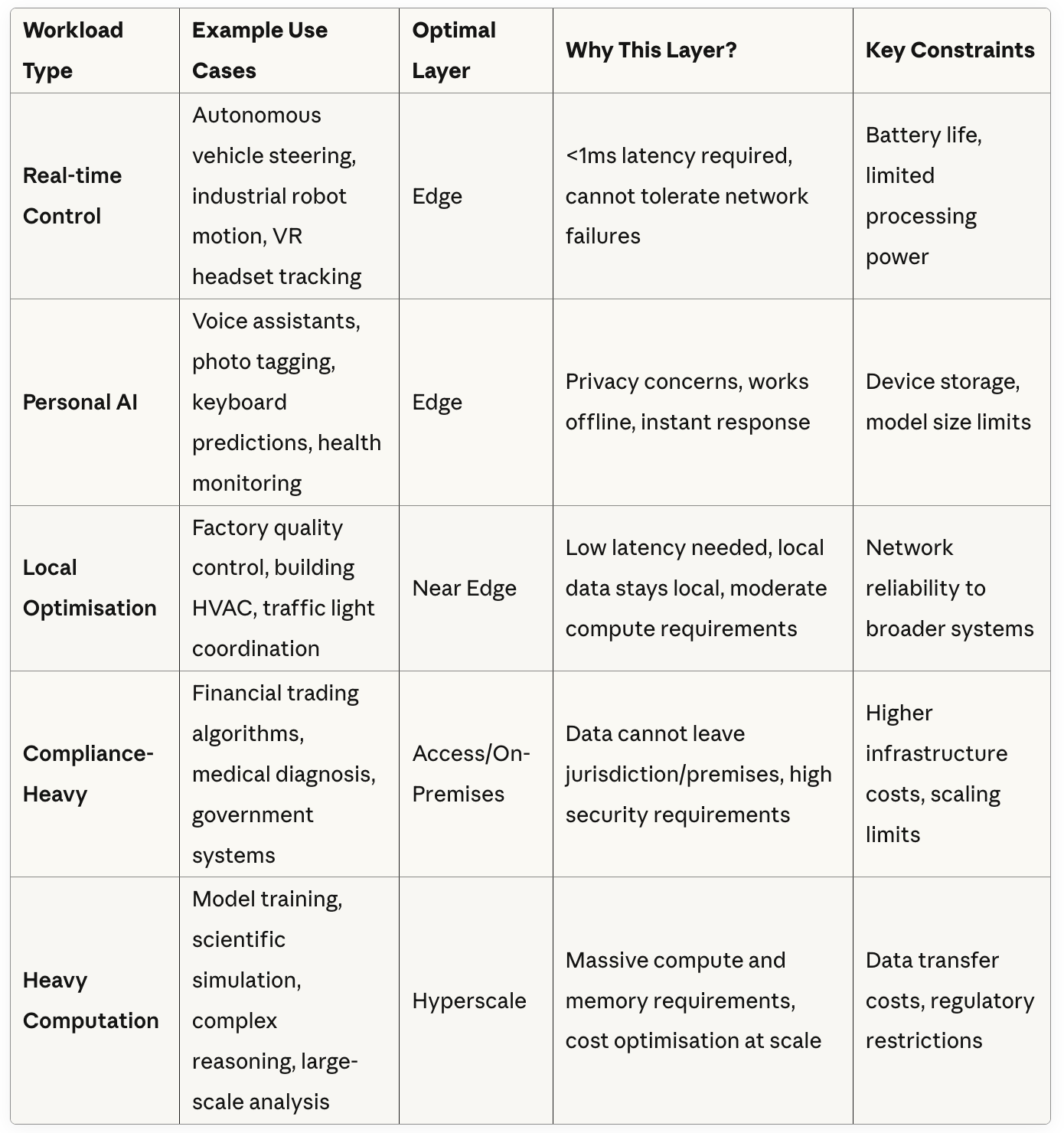
Most systems will blend these approaches rather than choosing one layer exclusively. A robot might process vision and motion locally while calling regional or cloud services for higher-order planning. An autonomous vehicle cannot wait for round trips to hyperscale datacenters, just as a mulit-trillion-parameter models cannot run on drone batteries. Some workloads will always demand heavy, centralized, power-hungry infrastructure. Others will be light, local and frugal.
The opportunity lies not in treating this as a zero-sum race for megawatts but in shaping the stack so each task finds a home along The Compute Gradient. That shift, and building for it, is where competitive advantage emerges.
iii. UK Strategy
Where does this leave the UK? Current electricity prices will make it hard to attract the kind of hyperscale datacentre investments now flowing to the Nordics, Ireland or the US. Last week’s announcements, with nScale partnering with NVIDIA and OpenAI to build UK capacity – is a positive signal, but is still small in global terms. The UK will need some large datacentres, but it does not need to dominate that game. There are other parts of the stack where Britain can play. Arm remains the most important piece of processor IP outside the US. Around it sit a cluster of computing startups across logic, memory, and networking. Compiler expertise is strong in universities. With procurement nudges and targeted co-funding, the UK could become an edge-efficiency leader rather than chasing hyperscale status.
Lawrence (me again, hi), put his cards on the table earlier this month:
“Instead, be the only country in the world that can do X. Make X critical to the AI tech stack. Then say: you only get X if we get Y. That's geopolitics. You’re welcome. And for the U.K: “X” is compound semiconductors and photonics.”
The real question is not whether AI lives in the cloud or at the edge, but which use cases demand which kind of “intelligence”. Thinking Fast or Thinking Slow. A driverless car cannot wait on a round trip to a hyperscale datacentre, just as a trillion-parameter model cannot run on a drone battery. Some workloads will always be heavy, centralised and power-hungry; others will be light, local and frugal.
The opportunity is to stop treating this as a zero-sum race for megawatts and instead to shape the stack so each task finds its natural home.
That shift is where advantage lies. The nations and companies that figure out how to match workload to The Compute Gradient will be the ones that set the terms of the AI age.
The “win” isn’t bigger datacentres; it’s smarter/programmable placement so each workload lands at the cheapest and fastest point on The Gradient.
—
#thegradient #innovation #technology
 |
|
This is a great discussion! I think you forgot to note one crucial point, which actually makes your argument much stronger (and improves the "compute gradient" overall). I think the biggest question about the high-scale AI workloads of the future is not just "where does it run" but "what does it run". Some tasks require big models, some only need small models, some need small-but-specialized models, etc. .
Right now we do have AI model orchestrators dealing with this issue, but they're not very good at this. As time goes on, and the capabilities of top-end AI models grow stronger, we'll see a much stronger "capabilities gradient". So when you take an inventory of the usage of a professional, it won't be "10,000 queries", it will be "9000 small-model cheap queries, 900 larger-model queries, and 100 huge-model queries". Many of the 9000 will run on the edge, but the 100 huge-model queries will run serverside. Regardless, the electricity cost won't be simply 10,000 times the cost of a single query, but something much more nuanced, with a lot of efficiencies gained using this.
The details are still uncertain. I personally think it's true that the future is bottlenecked by electricity production. I think AI will end up consuming a very large amount of our electrical output, and that electrical buildout is crucial. But I think that analyzing the numbers and growth rate is very hard. In other words: I think the future does get bottlenecked by electricity production, and at some future year X, the more electricity you produce, the more value you can create, with an almost linear relationship between the two. But I don't know the value of X. I could see X being 2030, but I could also see it being 2035 or 2040. I think it'll definitely happen by 2040. (And given the timelines of infrastructure projects, I guess even X=2040 means "we should start the buildup immediately and aggressively").
This seems to fit maybe with the argument advanced here? https://www.dailymaverick.co.za/opinionista/2025-09-22-where-does-ai-go-from-here/?utm_source=Sailthru&utm_medium=email&utm_campaign=first_thing