


Decentralised AI (Feat. Richard Blythman of Naptha)
Everything you need to know about Decentralised Agents w/ Richard Blythman of Naptha #crypto #ai


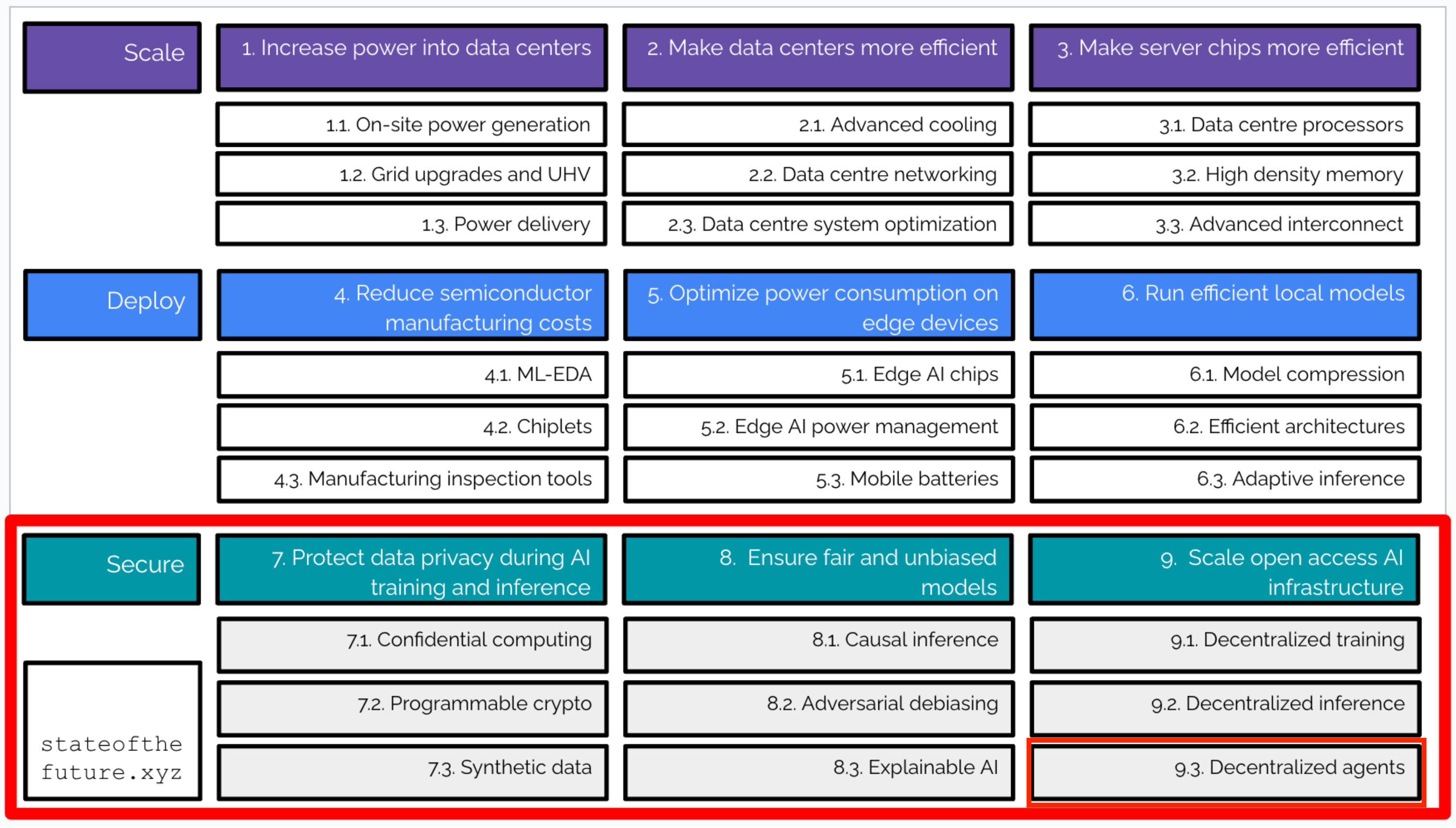
Weirdly as part of my “AI” thesis, I included 9.3. Decentralised agents. Why you might plausibly ask? Well because crypto x AI is a cool meme? Partly yes, but also because:
"…decentralized agents represent a frontier in AI, blending autonomous decision-making capabilities with distributed systems. Current state-of-the-art agent frameworks like LangChain and AutoGPT showcase the potential of AI agents to perform complex, multi-step tasks with minimal human intervention. We should expect OpenAI O1 and the associated scaling pathway to make more sophisticated agents economically viable going into 2025. For agents to run on blockchains, more work is needed on verifiable computing, agent transactions, and intern-agent communication. Sorry to say we need more infrastructure, it’s always more infrastructure with crypto I know, and yes we need actual users soon. But maybe the users are actually AI not humans? Maybe everyone has it wrong. Maybe crypto was never for humans. Maybe we were supposed to build infrastructure for agents all along. Is this actually how AI wins? It’s already got us building a computational substrate for it to become economically productive and accumulate wealth? What have we done?
It’s Feb 5th 2025 and we have o3+DR and Operator from OpenAI, agents are happening. I have always strongly believe agents using crypto substrates is the #killerapp. And when I say always, I mean since 2016, a solid 9 years ago. Have a look at this monster from the “Blockchain-enabled Convergence”:

Not bad huh? In 2025, we are talking about agents and agentic workflows, if you squint that fits neatly as “oracle/ANI” in the business process layer. Nine years early man. If you want to know what to invest in in 2034, I’m your man.
This week I spoke to Richard Blythman of Naptha about where we are with agents on blockchains aka decentralised agents / dAgents (i think i just coined that term). Naptha is a modular AI platform for autonomous agents that enables developers to build AI applications, conduct AI research, and scale cooperative AI agents on the agentic web.
We discuss a vision for AI focused on decentralized networks of agents rather than single, centralized AI system. Including the technical challenges of building infrastructure for agent-to-agent communication, orchestration, and privacy, with particular focus on why blockchain technology might be necessary for this architecture.
Key Takeaways:
Novel AGI Architecture: Richard presents a contrarian view to the mainstream "single AI system" approach, suggesting that AGI will emerge as a network of interacting agents running on edge devices rather than centralized data centers. This challenges both OpenAI's fully centralized and Apple's hybrid approaches.
Workflow Privacy as Critical IP: A fascinating insight is that protecting workflow privacy might be more important than data privacy. While data can be protected through various means, the actual sequences and patterns of how agents solve problems (workflow IP) represent valuable intellectual property that could make human problem-solving obsolete if centralized in one company.
Blockchain's Role in Agent Economics: The interview suggests that blockchain technology's key value isn't primarily about decentralization or data privacy, but rather about enabling microtransactions between agents. Traditional payment infrastructure like Visa/Mastercard isn't suitable for the high-frequency, small-value transactions that would occur between millions of interacting AI agents. This reminded me of what Nevermined are doing.
gm Richard, let’s get into the meat of it, what is Naphtha solving?
At a very high level, we've believed for a long time that scaling the model size is going to run out, and we actually need other innovations to get to AGI. OpenAI are starting to talk about this too. They just came out in the news talking about this new approach, which is related to teaching models to think, not just focusing on the model but the kind of systems running the model. What we think they're missing is that AGI won't be a single entity. The way that everyone sees it in the world is AI as the single godlike entity. We actually think AGI is going to be more like a network of interacting agents.
AGI is gonna be more like a network of agents rather than a thing, so like an economy not a company?
Exactly. We think first of all, AGI is going to be multiple entities interacting. And we don't think they're going to run on a cloud's data center. Because a lot of the research we're seeing shows that diversity or heterogeneity is important. And we think these networks of agents are going to need to have a lot of heterogeneity.
And the way to do that isn't to run them all on a single cloud data center, but to run them on these edge devices with access to local data.
In which case, what needs to be built exactly? And why can't they be done today?
So a lot of it is the communication infrastructure. We haven't started to develop standards for these agents. There's one organization called the AI Engineering Foundation which came out of San Francisco. They held the AI Engineering Summit and their role was to start to build standards for agents. One of the first standards they came up with was something called agent protocol, which is basically just like a REST API with different endpoints like create task, for example. The communication layer is just a REST API, but you need to agree on what the endpoints are. Like, create task, and what sort of data would you pass to create task - natural language? Is it JSON? Is it something else?
These standards between cooperating agents haven't been agreed upon yet. So that's one of the things we're working on are the various different communication options, like REST API, WebSockets, gRPC. We support all of these. And then on top of that, we're creating this standard interface for how these agents can request tasks from each other or other things like that.
How is this different from LangChain or BabyAGI or one of the existing agent frameworks?
All communication in existing agent frameworks happens locally. Because all of the functions are on the same device, you can basically just call that function directly from that single device. All of our communication has to happen via API interface because it has to run on different nodes. That's one of the key differences. We don't consider ourselves an agent framework. We're agnostic of agent framework. The idea is that you can prototype locally in whatever agent framework you want, whether it's Crew AI or LangChain. And then you deploy with us during deployment. It's almost synonymous with being accessible via API. You can deploy this prototype agent that you've built, and then that agent will communicate with other agents via API interfaces. This means you can use any agent framework because they're communicating via API.
What's the closest parallel in crypto? We are getting there but inetroperability is a long standing problem in crypto. What's your mental model as to why it hasn't been solved? Or what we learned from that that we can think about for agent communication?
Projects like Ocean Protocol were along the right lines to a large extent. I think tokenizing these assets on the blockchain was the right thing, and Ocean mostly focused on datasets. You could build algorithms on the blockchain as well, but they never went as far as doing services. Instead, their algorithms were just like a Python file that you could tokenize and index on the blockchain. Nevermined have focused on publishing AI services on the blockchain, which is particularly useful for us. We work closely with them.
One of the key problems to solve is how the agents communicate via AI services. We're using them to publish these endpoints on the blockchain and provide access control along with the payments. It's a really good starting point and a few people are trying to create these registries for AI services in the crypto space now. What they don't provide is the orchestration behind those. We see them as the registry for these AI services, and then we are like an engine that orchestrates calls to many of these AI services - like workflow orchestration.
What's the key engineering challenge in that orchestration? When you say orchestration, I think of heterogeneous hardware, heterogeneous frameworks, diversity of endpoints. How much of that is solved when you just deal with some level of abstraction? And therefore, you don't need to worry about all of that heterogeneity?
We're like a layer on top of AI services. In the traditional cloud stack, you have services like AWS, you have this services layer, and then you have the layer above which is the orchestration of those services. If you think of an app like Netflix, they have thousands of microservices and often every user action requires multiple services. It could be as simple as calling one service after another service after another service. But maybe there's also some optimization - maybe you can parallelize some of them to make it really efficient. That's ultimately the goal of workflow orchestration.
Imagine if you have a workflow that requires thousands or millions of agents - increasing the efficiency there and calling them in parallel rather than sequential becomes super important. That's basically what we're trying to do. We're trying to orchestrate calls to millions or billions of agents which allows them to work together to cooperate on these tasks.
Okay, so each person, each company has access to 1000 agents. We can call them vertical SaaS, we can call them microservices, whatever. But each of them are running around and they need orchestration. If that is the world that exists, why does it need to be decentralized? Why does it need to run using crypto? Because I can imagine if I had this conversation with one of the many new agent framework companies, very few of them come from the crypto world or use blockchain substrates. So why is that the better entry point?
The main answer is that the orchestrator has a lot of power. OpenAI are trying to do the fully centralized approach, which is trying to build this agent hub - the GPT Store - where all of the agents in the world will be. I'm sure at some point they will start to do orchestration. At the moment you can only call a single agent, but it will be easy to expand to multi-agent systems.
That's one possible world where everyone uploads their agents to OpenAI and OpenAI does all of the orchestration. There's a middle ground, which is what I think Apple are trying to do - some of the compute happens at the edge, but maybe you have this Apple Cloud that still acts as the orchestrator, organizing the logic and order in which you make calls to Apple devices running at the edge.
That's still a lot of power to give Apple because they get to see a lot of the states of each workflow, maybe some data, all that sort of stuff. The reason I don't think either of those are viable is because agents are going to do more and more stuff for us as humans. The more data that we give to these agents, the better their performance is going to be in the tasks we want them to perform. Maybe I want my agent to look after my health, maybe I want it to look after my personal finances. There's really no area of my life that an agent wouldn't help.
Am I happy to upload all of this data to OpenAI? Or for Apple to orchestrate how my agents would access and interact with personal data? I think it's going to have to be at the edge. We already give enough data to these companies. WhatsApp has my messaging data, maybe some health tech app has my health data, but this is about putting all that data together. Imagine a single entity had access to all my health data, all my messaging data, all my finance data - they could basically clone you. That's kind of a scary prospect.
We have the Apple Cloud Compute doing its absolute best to protect privacy and doing a pretty good job. But how much of this could be solved by multi-party computation or just federated learning? Would that not be enough to resolve the challenges of keeping OpenAI honest? A different world model is there is the cloud provider but all of your data is private. And both for training and inference. Does that also solve the problems?
We're more federated at the moment. We haven't fully decentralized orchestration yet. It still happens through orchestrator nodes, but we're working on putting that on the blockchain to be fully decentralized. I think Apple will do a good job of keeping the data private. I think the reason that it doesn't work is not because of data privacy - those issues can probably be solved - but what I call workflow privacy or workflow IP. Imagine I want to cooperate with other devices on the network. What I would submit to the orchestrator node is workflow logic for how I want my agents to interact with everyone else's agents. You can't keep that private from the orchestrator nodes. The orchestrator needs to know if my agent is to interact with other agents.
Think about me working for a company. I have a lot of my personal data and personal knowledge, but actually a lot of what's valuable when I'm working in a company is the workflow - the way that I solve things. If a company had access to not my personal data, but the workflow of how I tend to solve problems, that's really valuable. If they had that, they could solve problems in the same way that I solved them, which kind of makes me obsolete.
If someone knows how I solve problems, they can just use that workflow logic, that program that I use to solve problems with some other personal data, and do a lot of the same work that I do. This workflow IP, these processes of how we solve problems, is actually really valuable. If we don't want to end up in a world where one organization knows all the processes for how to solve everything, then we need to keep that private too.
My mind immediately goes to MPC as the solution to collaboratively processing over encrypted data. In theory, Multiple agents could participate in a secure MPC protocol where each agent's workflow logic is treated as private input?
Maybe but MPC isn’t ready for this yet and it’s unclear if it ever will be for arbitary operations and millions of agents. As more agents join the computation or as workflows become more complex, the computational overhead grows exponentially. Each step requires multiple rounds of encrypted communication, creating a network traffic burden that could make real-time interaction practically impossible. Also as far as I know, MPC works best with predetermined computational circuits, but agent workflows are dynamic and branching. But if MPC does become viable, as the orchestrator, there is nothing stopping Naphtha from just integrating the agents using MPC protocols are part of the solution when it’s ready.
Okay, let’s imagine a world in which we do have agents interacting with MPC protocols to protect workflow logic. Why both with a blockchain? I’ve argued that crypto might actually never become the compute infrastructure for humans because of inertia and p/ath dependancy, but we don’t have those problems for agents. Internet money is best when you don’t interact with the real-world, and agents in many cases will never need to.
I think so too. We've discussed this quite a bit. There's a really good argument for why Visa isn't good enough for the payments layer for agents. That's also something that hasn't been ready up until now. We've been working on it with Nevermined for a long time, but they're still iterating on the payments protocol for agents, and we don't even know if we can scale that yet.
That's basically what we're trying to put together - different layers of the stack, whether it's payments or identity or data protocols. We're not focusing on any one of these. We're more like an orchestrator of all of these. That's basically what middleware is - it connects different technologies and sits in the middle. We want to be the middleware, the glue between payments, identity, data protocols, privacy tech. So that's quite a big challenge, putting all of these together.
Hell of a challenge man, good night and good luck.
Debrief
Richard essentially suggests that while the technical challenges of inter-agent communication are important, the real opportunity might lie in the layers above - particularly in solutions that can handle workflow privacy, enable efficient microtransactions, and manage heterogeneous networks of agents. This is a somewhat different emphasis than my thinking about the communication layer like IPFS and libp2p.
Also interestingly he suggests a distinction between workflow privacy as distinct from data privacy, and that in fact, workflow privacy is just as important to protect and we don’t have good solutions yet.
This speaks to 🔑7.2. Programmable Crypto and the need for MPC standards or encrypted collaborative processing protocols that offer developers a level of abstraction to work on a la Data Fusion and Iceberg.